

Decision tree learning is an extraordinarily important algorithm for AI because it is very powerful, but also simple and efficient for extracting knowledge from data.
Compared to the Data Analysis and Case-Based Reasoning learning algorithms, it has an important advantage. The extracted knowledge is not only available and usable as a black box function, but rather it can be easily understood, interpreted, and controlled by humans in the form of a readable decision tree. This also makes decision tree learning an important tool for data mining.
We will discuss function and application of decision tree learning using the C4.5 algorithm. C4.5 was introduced in 1993 by the Australian Ross Quinlan and is an improvement of its predecessor ID3 (Iterative Dichotomiser 3, 1986). It is freely available for noncommercial use. A further development, which works even more efficiently and can take into account the costs of decisions, is C5.0.
The CART (Classification and Regression Trees, 1984) system developed by Leo Breiman works similarly to C4.5. It has a convenient graphical user interface, but is very expensive.
Twenty years earlier, in 1964, the CHAID (Chi-square Automatic Interaction Detectors) system, which can automatically generate decision trees, was introduced by J. Sonquist and J. Morgan. It has the noteworthy characteristic that it stops the growth of the tree before it becomes too large, but today it has no more relevance.
| Variable | Value | Description |
| Ski (goal variable) | yes, no | Should I drive to the nearest ski resort with enough snow? |
| Sun (feature) | yes, no | Is there sunshine today? |
| Snow_Dist (feature) | <= 100, >100 | Distance to the nearest ski resort with good snow conditions (over/under 100 km) |
| Weekend (feature) | yes, no | Is it the weekend today? |
Table 8.4 Variables for the skiing classification problem
Also interesting is the data mining tool KNIME (Konstanz Information Miner), which has a friendly user interface and, using the WEKA Java library, also makes induction of decision trees possible. In Sect. 8.10 we will introduce KNIME.
Now we first show in a simple example how a decision tree can be constructed from training data, in order to then analyze the algorithm and apply it to the more complex LEXMED example for medical diagnosis.
A Simple Example - Is it is Worthwhile to Drive to Ski Resort in Mountains
A devoted skier who lives near the high sierra, a beautiful mountain range in California, wants a decision tree to help him decide whether it is worthwhile to drive his car to a ski resort in the mountains. We thus have a two-class problem ski yes/no based on the variables listed in Table 8.4.
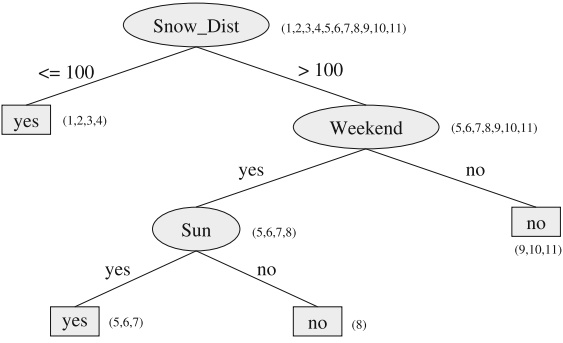
Fig. 8.23 Decision tree for the skiing classification problem. In the lists to the right of the nodes, the numbers of the corresponding training data are given. Notice that of the leaf nodes sunny = yes only two of the three examples are classified correctly
Figure 8.23 shows a decision tree for this problem. A decision tree is a tree whose inner nodes represent features (attributes). Each edge stands for an attribute value. At each leaf node a class value is given.
The data used for the construction of the decision tree are shown in Table 8.5. Each row in the table contains the data for one day and as such represents a sample. Upon closer examination we see that row 6 and row 7 contradict each other. Thus no deterministic classification algorithm can correctly classify all of the data. The number of falsely classified data must therefore be >= 1. The tree in Fig. 8.23 thus classifies the data optimally.
+How is such a tree created from the data? To answer this question we will at first restrict ourselves to discrete attributes with finitely many values. Because the number of attributes is also finite and each attribute can occur at most once per path, there are finitely many different decision trees. A simple, obvious algorithm for the construction of a tree would simply generate all trees, then for each tree calculate the number of erroneous classifications of the data, and at the end choose the tree with the minimum number of errors. Thus we would even have an optimal algorithm (in the sense of errors for the training data) for decision tree learning.<.p>
| Day | Snow_Dist | Weekend | Sun | Skiing |
| 1 | </=100 | yes | yes | yes |
| 2 | </=100 | yes | yes | yes |
| 3 | </=100 | yes | no | yes |
| 4 | </=100 | no | yes | yes |
| 5 | >100 | yes | yes | yes |
| 6 | >100 | yes | yes | yes |
| 7 | >100 | yes | yes | no |
| 8 | >100 | yes | no | no |
| 9 | >100 | no | yes | no |
| 10 | >100 | no | yes | no |
| 11 | >100 | no | no | no |
Table 8.5 Data set for the skiing classification problem
The obvious disadvantage of this algorithm is its unacceptably high computation time, as soon as the number of attributes becomes somewhat larger. We will now develop a heuristic algorithm which, starting from the root, recursively builds a decision tree. First the attribute with the highest information gain (Snow_ Dist) is chosen for the root node from the set of all attributes. For each attribute value ( </= 100, >100) there is a branch in the tree. Now for every branch this process is repeated recursively. During generation of the nodes, the attribute with the highest information gain among the attributes which have not yet been used is always chosen, in the spirit of a greedy strategy.
About the Author
Dr. Wolfgang Ertel is a professor at the Institute for Artificial Intelligence at the Ravensburg-Weingarten University of Applied Sciences, Germany.

This accessible and engaging textbook presents a concise introduction to the exciting field of artificial intelligence (AI). The broad-ranging discussion covers the key subdisciplines within the field, describing practical algorithms and concrete applications in the areas of agents, logic, search, reasoning under uncertainty, machine learning, neural networks, and reinforcement learning. Fully revised and updated, this much-anticipated second edition also includes new material on deep learning.
Topics and features:
• Presents an application-focused and hands-on approach to learning, with supplementary teaching resources provided at an associated website
• Contains numerous study exercises and solutions, highlighted examples, definitions, theorems, and illustrative cartoons
• Includes chapters on predicate logic, PROLOG, heuristic search, probabilistic reasoning, machine learning and data mining, neural networks and reinforcement learning
• Reports on developments in deep learning, including applications of neural networks to generate creative content such as text, music and art
• Examines performance evaluation of clustering algorithms, and presents two practical examples explaining Bayes theorem and its relevance in everyday life
• Discusses search algorithms, analyzing the cycle check, explaining route planning for car navigation systems, and introducing Monte Carlo Tree Search
• Includes a section in the introduction on AI and society, discussing the implications of AI on topics such as employment and transportation
Ideal for foundation courses or modules on AI, this easy-to-read textbook offers an excellent overview of the field for students of computer science and other technical disciplines, requiring no more than a high-school level of knowledge of mathematics to understand the material.
A reader says,"The book has a substantial introduction to logic that was very helpful. Overall the selection of topics was perfect for a first course in AI."
A reader says,"An excellent book for beginners. Would like to have seen code examples in python. I realize python is not much historic for AI but it is lingua franca for data science and deep learning today. Good treatment of many topics on search etc. Definitely a great resource for those just getting started in AI."
Click here for more information.
