

Let's start with an overview of the transformation process. The process starts with two documents, the XML document which contains the source data to be transformed, and the XSLT style sheet document which describes the rules of the transformation. While you can transform XML into nearly any format, I am going to use examples that return HTML.
To perform the actual transformation, you'll need an XSLT processor, or a browser that supports XSLT. Most current XML Editors have built-in XSLT support, as do most current Web browsers.
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="02-03.xsl"?> <ancient_wonders> <wonder> <name language="English">Colossus of Rhodes</name> <location>Rhodes, Greece</location> </wonder> </ancient_wonders>
Figure 2.1 This is a very basic XML document representing a single wonder of the world. Notice the xml-stylesheet processing instruction linking this XML document to an XSLT style sheet.
Analyzing the source XML
To begin, you'll need to link your XML document to your XSLT style sheet using the xml-stylesheet processing instruction (Figure 2.1). Then, when you open your XML document in an XSLT processor or a browser, the instruction tells the processor to perform the XSLT transformation before displaying the document.
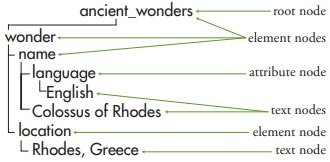
In the first step of this transformation, the XSLT processor analyzes the XML document and converts it into a node tree. A node tree is a hierarchical representation of the XML document (Figure 2.2). In the tree, a node is one individual piece of the XML document (such as an element, an attribute, or some text content).
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http:// www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="/"> <html><head><title>Wonders of the World</title></head><body> <h1>Wonders of the World</h1> The <xsl:value-of select="ancient_wonders/wonder/name"/> is located in <xsl:value-of select="ancient_wonders/wonder /location"/>. </body></html> </xsl:template> </xsl:stylesheet>
Figure 2.3 A very basic XSLT document to transform the XML document shown in Figure 2.1.
Assessing the XSLT style sheet
Once the processor has identified the nodes in the source XML, it then looks to an XSLT style sheet (Figure 2.3) for instructions on what to do with those nodes. Those instructions are contained in templates which are comparable to functions in a programming language.
Each XSLT template has two parts: first, a label that identifies the nodes in the XML document to which the template applies; and second, instructions about the actual transformation that should take place. The instructions, or rules, will either output or further process the nodes in the source document. They can also contain literal elements that should be output as is.
Performing the transformation
The XSLT transformation begins by processing the root template. Every XSLT style sheet must have a root template; this is the template the applies to the source XML document's root node. In Figure 2.3, the root template is defined with <xsl:template match = "/">. Within this root template, there may be other sub-templates which can then apply to other nodes in the XML document.
Figure 2.4 The final transformed HTML shown in Internet Explorer 7.
And the transformation continues until the last instruction of the root template is processed. The transformed document is then either saved to another file, displayed in a browser (Figure 2.4), or both.
While you can use XSLT to convert almost any kind of document into almost any other kind of document, that's a pretty vague topic to tackle. In this book, I am focusing on using XSLT to convert XML into HTML. This lets you take advantage of the strengths and flexibility of XML for handling your data, as well as the compatibility of HTML for viewing it.
Tips
• XSLT style sheets are text files and are saved with an .xsl extension.
• With some XSLT processors, you don't need an xml-stylesheet instruction in your XML document. Instead, you can assign your XSLT style sheet to an XML document.
• XSLT uses the XPath language to identify nodes. XPath is sufficiently complex to warrant its own chapters: Chapter 3, XPath Patterns and Expressions, and Chapter 4 XPath Functions in Learn more about XML: Visual Quickstart Guide at amazon.com.
About the Author
Kevin Howard Goldberg has been working with computers since 1976 when he taught himself BASIC on his elementary school's PDP 11/70. Since then, Kevin's career has included management consulting, lead software development and in his current capacity, he runs technology operations for a world-class Internet Strategy, Marketing and Development company. Kevin holds a bachelor's degree in Economics and Entrepreneurial Management from the Wharton School of Business at the University of Pennsylvania, and is a candidate for a master's degree in Computer Science at the University of California, Los Angeles.

Reader J. Hatch says, "This book is a great way to get started if you have not done a lot of HTML and are looking for a way to get your feet wet with XML and it's interactions with HTML. It does a great job of step-by-step leading you through most of the basic concepts used in XML. If you don't know much about XML and want to get started and need a quick reference for figuring out what is going on in an XML file, this is a great starting point. It is compact and the approach is to explain something minimally and then show a example. There are example files to download that the book references. To get the most out of this book, you will have to download the examples."
