

Memory is central to the operation of a modern computer system. Memory consists of a large array of bytes, each with its own address. The CPU fetches instructions from memory according to the value in the program counter. These instructions may cause additional loading from and storing to specific memory addresses.
A typical instruction-execution cycle, for example, first fetches an instruction from memory. The instruction is then decoded and may cause operands to be fetched from memory. After the instruction has been executed on the operands, results may be stored back in memory. The memory unit sees only a stream of memory addresses; it does not know how they are generated (by the instruction counter, indexing, indirection, literal addresses, and so on) or what they are for (instructions or data). Accordingly, we can ignore how a program generates a memory address. We are interested only in the sequence of memory addresses generated by the running program.
Main memory and the registers built into each processing core are the only general-purpose storage that the CPU can access directly. There are machine instructions that take memory addresses as arguments, but none that take disk addresses. Therefore, any instructions in execution, and any data being used by the instructions, must be in one of these direct-access storage devices. If the data are not in memory, they must be moved there before the CPU can operate on them.
Registers that are built into each CPU core are generally accessible within one cycle of the CPU clock. Some CPU cores can decode instructions and perform simple operations on register contents at the rate of one or more operations per clock tick. The same cannot be said of main memory, which is accessed via a transaction on the memory bus. Completing a memory access may take many cycles of the CPU clock. In such cases, the processor normally needs to stall, since it does not have the data required to complete the instruction that it is executing.
This situation is intolerable because of the frequency of memory accesses. The remedy is to add fast cache memory between the CPU and main memory, typically on the CPU chip for fast access. To manage a cache built into the CPU, the hardware automatically speeds up memory access without any operating system control. During a memory stall, a multithreaded core can switch from the stalled hardware thread to another hardware thread.
Not only are we concerned with the relative speed of accessing physical memory, but we also must ensure correct operation. For proper system operation, we must protect the operating system from access by user processes, as well as protect user processes from one another. This protection must be provided by the hardware, because the operating system doesn't usually intervene between the CPU and its memory accesses (because of the resulting performance penalty). Hardware implements this production in several different ways, here, we outline one possible implementation.
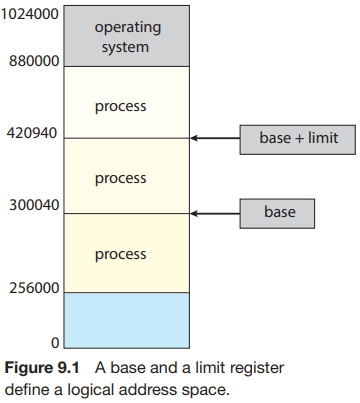
We first need to make sure that each process has a separate memory space. Separate per-process memory space protects the processes from each other and is fundamental to having multiple processes loaded in memory for concurrent execution. To separate memory spaces, we need the ability to determine the range of legal addresses that the process may access and to ensure that the process can access only these legal addresses. We can provide this protection by using two registers, usually a base and a limit, as illustrated in Figure 9.1. The base register holds the smallest legal physical memory address; the limit register specifies the size of the range. For example, if the base register holds 300040 and the limit register is 120900, then the program can legally access all addresses from 300040 through 420939 (inclusive).
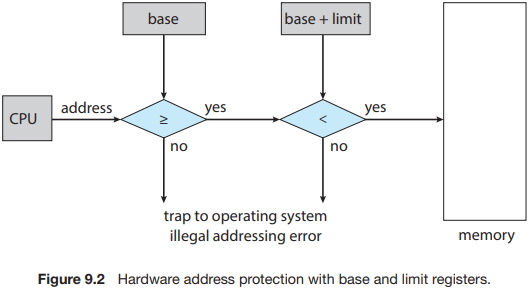
Protection of memory space is accomplished by having the CPU hardware compare every address generated in user mode with the registers. Any attempt by a program executing in user mode to access operating-system memory or other users' memory results in a trap to the operating system, which treats the attempt as a fatal error (Figure 9.2). This scheme prevents a user program from (accidentally or deliberately) modifying the code or data structures of either the operating system or other users.
The base and limit registers can be loaded only by the operating system, which uses a special privileged instruction. Since privileged instructions can be executed only in kernel mode, and since only the operating system executes in kernel mode, only the operating system can load the base and limit registers. This scheme allows the operating system to change the value of the registers but prevents user programs from changing the registers' contents.
The operating system, executing in kernel mode, is given unrestricted access to both operating-system memory and users' memory. This provision allows the operating system to load users' programs into users' memory, to dump out those programs in case of errors, to access and modify parameters of system calls, to perform I/O to and from user memory, and to provide many other services. Consider, for example, that an operating system for a multiprocessing system must execute context switches, storing the state of one process from the registers into main memory before loading the next process's context from main memory into the registers.
To learn more about logical and a physical memory addresses, memory address translation, and memory paging, see The tenth edition of Operating System Concepts.
About the Authors
Abraham Silberschatz is the Sidney J. Weinberg Professor of Computer Science at Yale University. Prior to joining Yale, he was the Vice President of the Information Sciences Research Center at Bell Laboratories. Prior to that, he held a chaired professorship in the Department of Computer Sciences at the University of Texas at Austin.
Professor Silberschatz is a Fellow of the Association of Computing Machinery (ACM), a Fellow of Institute of Electrical and Electronic Engineers (IEEE), a Fellow of the American Association for the Advancement of Science (AAAS), and a member of the Connecticut Academy of Science and Engineering.
Greg Gagne is chair of the Computer Science department at Westminster College in Salt Lake City where he has been teaching since 1990. In addition to teaching operating systems, he also teaches computer networks, parallel programming, and software engineering.

The tenth edition of
Operating System Concepts
has been revised to keep it fresh and up-to-date with contemporary examples of how operating
systems function, as well as enhanced interactive elements to improve learning and the student's
experience with the material. It combines instruction on concepts with real-world applications
so that students can understand the practical usage of the content. End-of-chapter problems,
exercises, review questions, and programming exercises help to further reinforce important
concepts. New interactive self-assessment problems are provided throughout the text to help
students monitor their level of understanding and progress. A Linux virtual machine (including
C and Java source code and development tools) allows students to complete programming exercises
that help them engage further with the material.
A reader in the U.S. says, "This is what computer-related books should be like. It is thorough, in depth, information packed, authoritative, and exhaustive. You cannot get this kind of excellent information from the Internet - or many other computer books these days. It's a shame that quality computer books are declining so rapidly in number. I hope they continue to update and publish this book for many years to come.

More Computer Architecture Articles:
• AMD's Phenom Processor
• Monolithic Kernel vs Microkernel vs Hybrid Kernel
• The Computer's Chipset
• Operating System Memory Management
• Logical Versus Physical Memory Addresses
• Capacitors in DC Circuits
• Multi-Processor Scheduling
• Expanding the Resources of Microcontrollers
• Microcontroller Registers
• Operating System Services